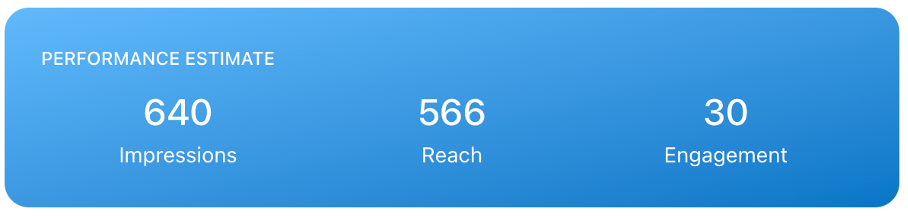
Six months have passed since we rolled out the Luceena Prediction Feature. Back then, we referred to the old dilemma attributed to Henry Ford, who famously said that 50% of his marketing was wasted, but he just didn’t know which 50%.
We all know that marketing and communication don’t always work out as planned and conceptualized. There are simply unknown variables that sometimes throw a wrench in the works. Of course, there are already solutions in the performance sector, such as Google AI campaigns and A/B testing, or more traditional methods like focus groups that review and assess an entire campaign.
With Luceena, we wanted to take a different approach—one that meets the demands of brand building and performance while also reflecting the speed of digital communication. That’s why we conceptualized our Prediction Feature last year and launched it live in January.
We don’t want to go into too much detail here, as it is, of course, one of the features of Luceena that gives us a competitive edge in the market. However, we can disclose the following: The model includes (in its final version) 11 different evaluation clusters that contribute to the calculation of a post’s success prediction. These include, for example, the ‘Image Appeal,’ the tone of the caption, the posting time, and even the weather.
The current model was trained with just over 80,000 posts from Instagram and LinkedIn, focusing on the industries that correspond to the largest user accounts of Luceena. In the world of AI training, with speculations about around 100 trillion training data points for GPT-4 by OpenAI, this is not much. But after more than six months and just over 2,000 posts analyzed and evaluated by Luceena, we can say that our current model is already impressive.
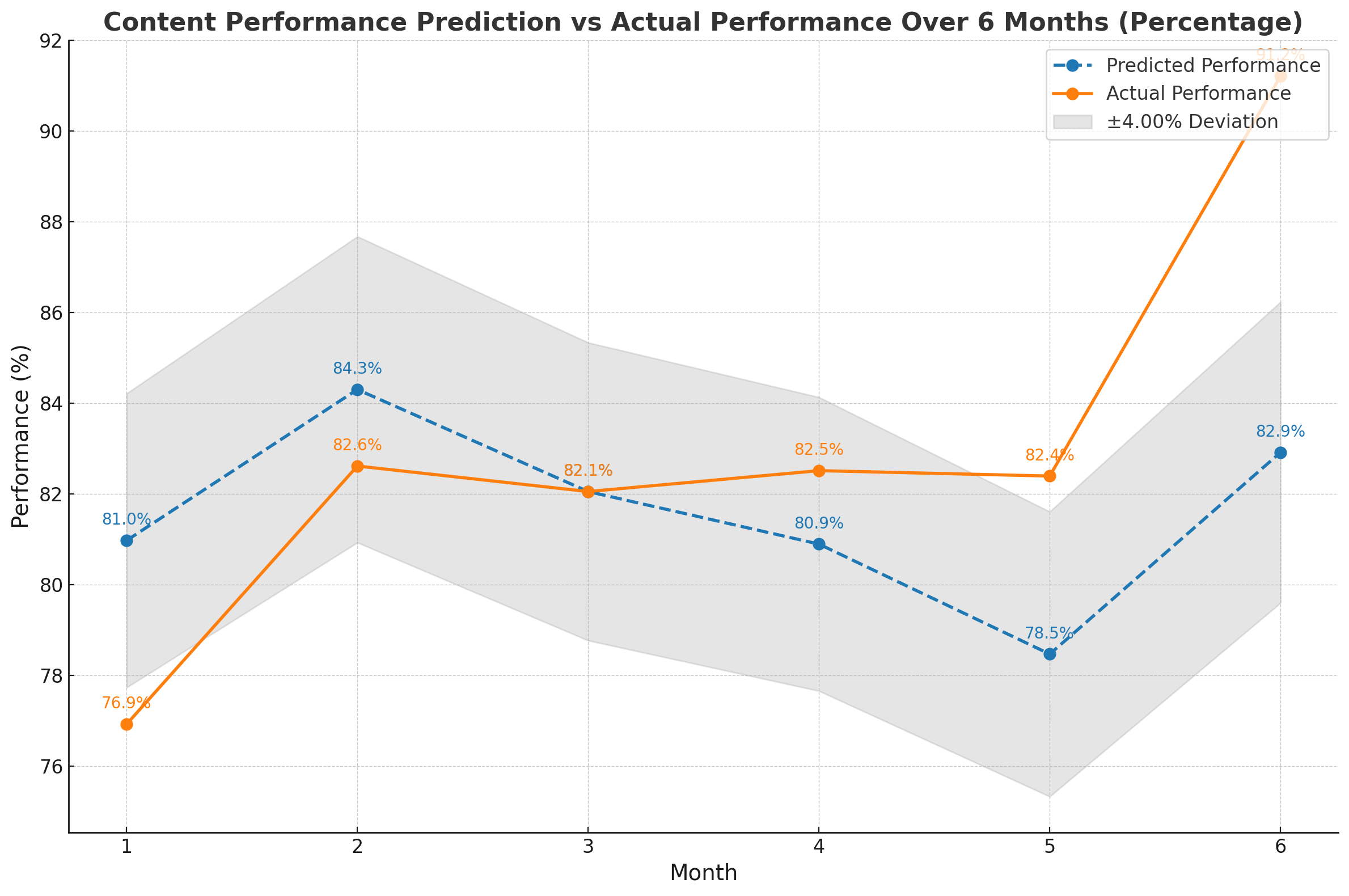
Within the two industries on which the majority of the training data is based, we have an accuracy prediction of ±10% on the actual performance (engagement, reach) of a post. When we move away from these industries, we still remain in a very good corridor of ±20%.
The good thing about the model is that it learns; every post submitted through Luceena, for which we can pull performance data after posting (there are legal aspects to this), improves the model.
Additionally, what’s interesting about our data is the prediction throughout the year. As expected, it slightly decreases with better weather. Although our training data includes retrospective information over an entire year, we likely couldn’t predict the summer accurately due to the limited amount of data. The European Championship (June 14 – July 14) also had a negative impact on accuracy. We will definitely keep an eye on that.
Leave A Comment